
Large Language Models (LLMs) have revolutionized how we interact with software, but running them at scale can be expensive and slow. A new technique called Prompt Caching (often referred to as Context Caching or Prefix Caching) is emerging as a powerful solution to these problems, offering up to 10x cost reductions and significantly lower latency for repetitive tasks.
In this guide, we'll explore the technical mechanics behind prompt caching, from the basics of LLM architecture to the implementation of Key-Value (KV) caching.
The Bottleneck: How LLMs Process Text
To understand why prompt caching is necessary, we first need to look at how LLMs process input.
At their core, LLMs are giant mathematical functions. They take a sequence of numbers (tokens) as input and produce a number as output. This occurs in a loop:
- Tokenization: The text prompt is converted into integer tokens.
- Embedding: Tokens are converted into vector embeddings.
- Transformation: The embeddings pass through layers of the transformer, utilizing "Attention" mechanisms to understand context.
- Output: The model predicts the next token.
- Loop: The new token is appended to the input, and the entire process repeats.
The Inefficiency of Repetition
In a standard inference loop, every new token generation triggers a re-processing of the entire sequence history. If your prompt is "The quick brown fox" and the model generates "jumps", the next iteration processes "The quick brown fox jumps".
While the model needs the context of the previous words, re-calculating the interactions (attention scores) between "The" and "quick" on every single step is redundant. These relationships don't change.
The Solution: KV Caching
This is where Key-Value (KV) Caching comes in.
Inside the transformer's attention mechanism, the model calculates three matrices for each token: Queries (Q), Keys (K), and Values (V). The attention score is derived from the interaction of these matrices.
Crucially, the K and V matrices for past tokens remain constant. By caching these matrices in GPU memory, the model only needs to compute the Q, K, and V for the newest token, and then attend to the cached K/V pairs of the history.
This optimization is standard in almost all efficient LLM inference engines today. It changes the complexity of generating a token from being proportional to the context length to being nearly constant.
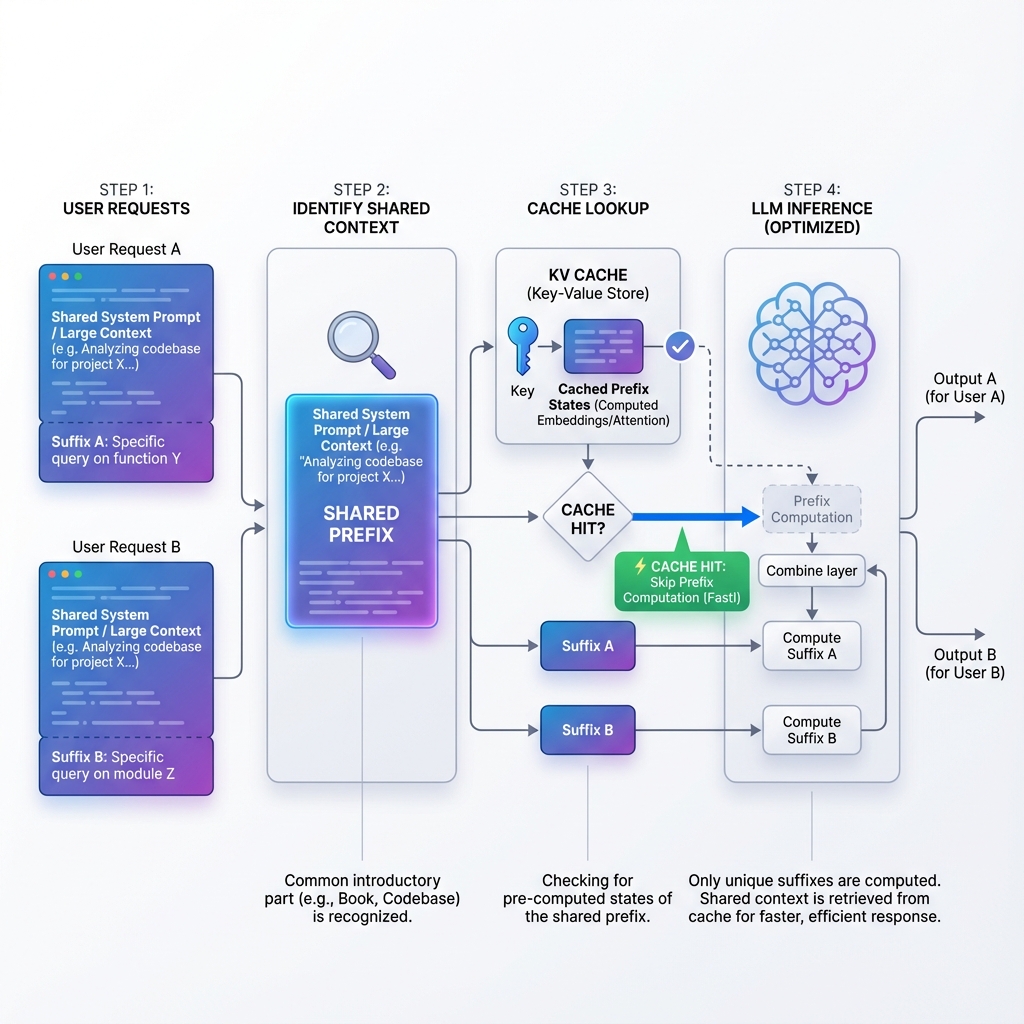
Prompt Caching: Extending KV Cache to the API level
Prompt Caching takes this internal optimization and exposes it across API requests.
Typically, when you send a request to an LLM API (like OpenAI, Anthropic, or Google Gemini), the server spins up a fresh state. Even if you send the same massive 50-page system prompt ten times in a row, the model re-computes the KV cache from scratch ten times. This redundancy is the primary driver of high LLM inference costs and latency.
With Prompt Caching, the API provider keeps the KV cache "hot" in memory for a short period (e.g., 5-10 minutes). If a new request arrives that matches the prefix of a cached prompt, the provider can skip the expensive initial processing phase completely.
How It Works
- First Request: You send a prompt with a large context (e.g., a codebase or a book). The model processes it fully (Cache Miss) and stores the KV states.
- Subsequent Requests: You send a new prompt that starts with the same large context. The system detects the match, loads the pre-computed KV states (Cache Hit), and immediately starts generating the response.
Benefits
- Cost Efficiency: Providers often offer a ~90% discount on cached input tokens because they save significant compute resources.
- Lower Latency: Time-to-First-Token (TTFT) is drastically reduced, as the model doesn't have to "read" the long prompt again. This leads to a much snappier user experience.
Use Cases for Prompt Caching
Prompt caching is a game-changer for workflows that involve heavy context reuse:
- Chat with Documents: When users ask multiple questions about the same uploaded PDF or manual.
- Code Assistants: Sending the same repository context with every user query.
- Agentic Workflows: Agents that run in a loop with a static system prompt and tools definition.
- Few-Shot Prompting: Using a long list of examples to guide the model's behavior.
Conclusion
Prompt caching represents a maturity in LLM serving infrastructure. It moves us away from brute-force re-computation towards a smarter, stateful interaction model. For developers, this means we can now build context-heavy applications—like advanced coding agents or deep document analysis tools—without being penalized by exorbitant costs or slow response times. By leveraging context caching, we can optimize LLM inference to be both faster and cheaper.
As models get larger and context windows expand to millions of tokens, techniques like prompt caching will become essential for building performant and sustainable AI applications.